Benchmark
Task: align a 2D Archimedean spiral to a 3D Swiss roll with the same angular parameterization. Quality metric: Spearman rank correlation between matched angular positions (1.0 = perfect alignment).
Large-Scale Results
End-to-end wall-clock time using distance_mode="landmark" and
mixed_precision=True.
NVIDIA H100 80 GB HBM3:
Scale |
Time |
Spearman ρ |
GPU Memory |
|---|---|---|---|
4,000 × 5,000 |
0.8 s |
0.999 |
0.7 GB |
10,000 × 12,000 |
4.1 s |
0.999 |
3.9 GB |
20,000 × 25,000 |
4.6 s |
0.999 |
16 GB |
30,000 × 35,000 |
9.3 s |
0.999 |
34 GB |
40,000 × 50,000 |
17 s |
0.999 |
64 GB |
45,000 × 45,000 |
18 s |
0.999 |
65 GB |
NVIDIA L40S 48 GB:
Scale |
Time |
Spearman ρ |
GPU Memory |
|---|---|---|---|
4,000 × 5,000 |
2.4 s |
0.999 |
1.1 GB |
10,000 × 12,000 |
3.0 s |
0.999 |
6.7 GB |
20,000 × 25,000 |
12 s |
0.999 |
18 GB |
30,000 × 35,000 |
25 s |
0.999 |
34 GB |
35,000 × 40,000 |
34 s |
0.999 |
45 GB |
Alignment quality (Spearman ≥ 0.999) is maintained across all scales. Maximum scale is bounded by GPU memory for the dense N×K transport plan; stable operation requires ≤ 80% VRAM utilization.
TorchGW vs POT
Scale |
Method |
Time |
Spearman ρ |
|---|---|---|---|
400 × 500 |
POT |
1.6 s |
0.999 |
400 × 500 |
TorchGW |
0.9 s |
0.998 |
4,000 × 5,000 |
POT |
183 s |
0.999 |
4,000 × 5,000 |
TorchGW |
1.0 s |
0.999 |
At 4,000×5,000, TorchGW is ~175× faster than POT with equal quality. At larger scales POT runs out of memory; TorchGW scales to 45k×45k on a single GPU.
Visualization
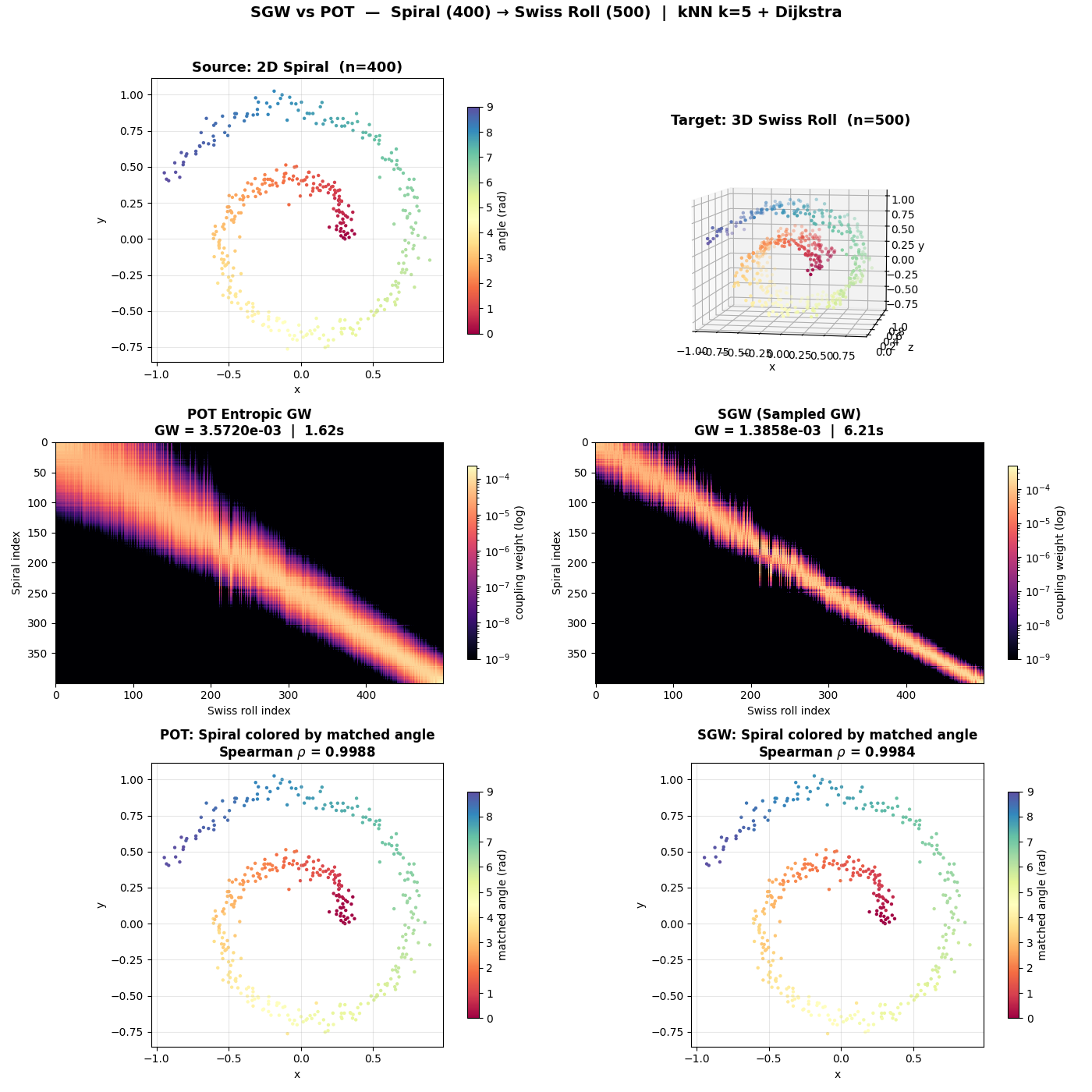
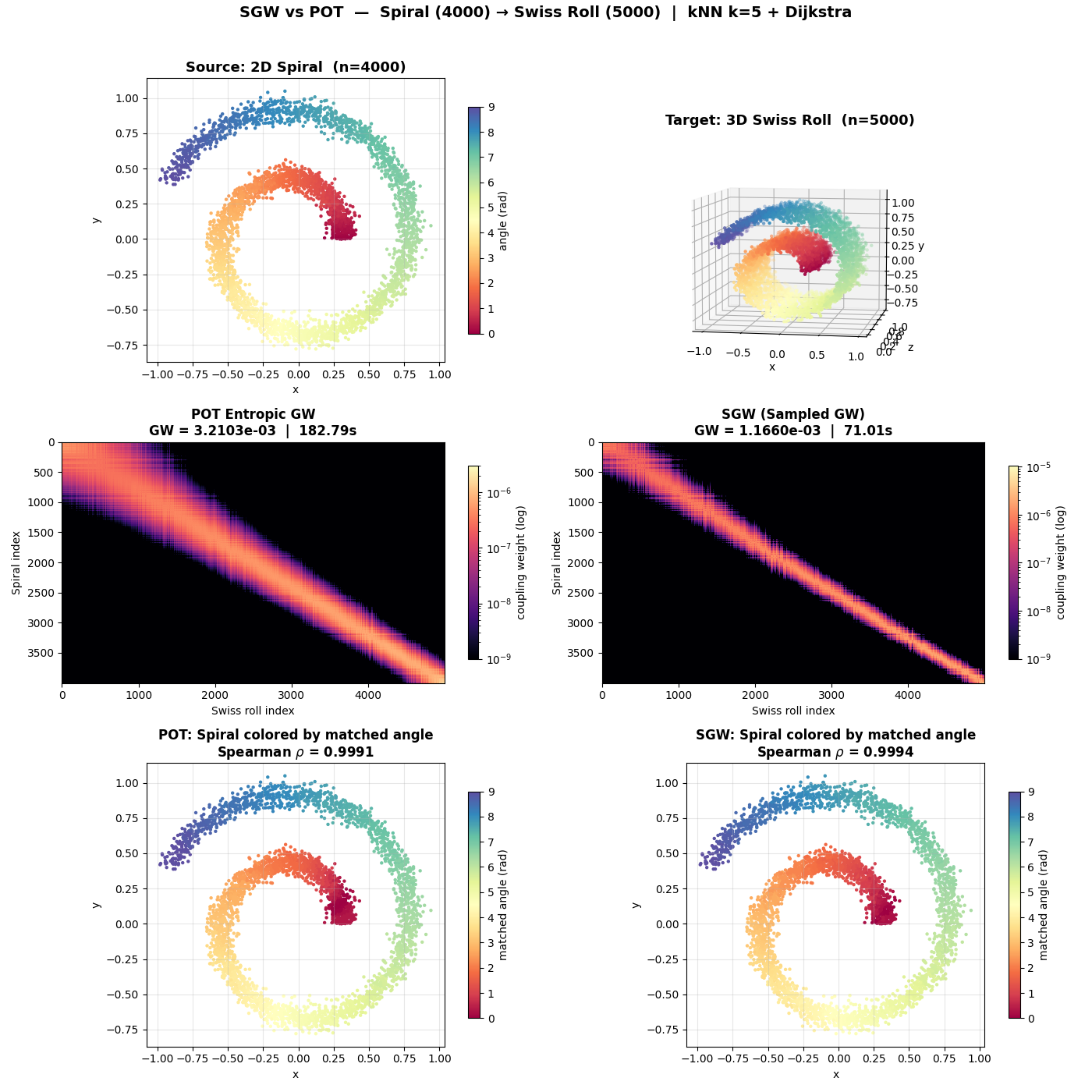
Reproducing
# Large-scale benchmark (TorchGW only)
python examples/benchmark_scale.py
# POT comparison (requires: pip install pot)
python examples/demo_spiral_to_swissroll.py